Welcome to the exciting world of databases! At least for the project in OpenStack I know best, which is Neutron. Neutron, and if I’m not wrong all the OpenStack projects, use SQLAlchemy as ORM library. Here you can read how this ORM was introduced in OpenStack to be the only API to talk to the databases (remember each project has it’s own database). To make this code public an accessible to all projects, oslo.db was created as a “handling library, [that] provides database connectivity to different database backends and various other helper utils”.
The abstraction level provided by those libraries allows any developer to communicate to the database just by using the oslo.db API, which uses SQLAlchemy under the hood. Only some leftovers, all of them related to migration code or compatibility checks, still use crafted SQL queries.
Quick usage description.
In a nutshell, the database session handling is achieved using the oslo_db.sqlalchemy.enginefacade system. A session belongs to a transaction context and all the reads and writes of this contexts will be executed on this single session. Any error within the context of the session will cause the session to emit a ROLLBACK.
oslo.db presents two kind of contexts: reader and writer. The second one should be used if we want to modify the database content.
Testing in two flavours.
In this script you will find the two small classes I use to test my database queries in Neutron:
- InMemoryDB: using the Neutron testing framework, inherits from BaseSqlTestCase class. This factory class creates a StaticSqlFixture. All classes inheriting from BASEV2 are database table definitions; this fixture will use those definitions to create the database schema. The fixture uses a SQLite in memory database. Any information stored will be lost once the process finishes.
- LocalDB: this class will connect to an existing database, using CONNECTION_URL. If you have a development deployment, the database will be accessed and any change will be persistent.
Refresh your SQL lessons.
The script mentioned has some examples extracted from the last patches I’ve submitted to the OpenStack Gerrit. The examples have a link to the code where those queries are used.
Let’s take the third one. When you use the Neutron API to create a port, the Neutron server will create several database registers, including one in “ports” table and another one in “ipallocations” table (if this is not a deferred IP port).
But if we create manually the port (something you should not do in the Neutron server code), we’ll need to create the port register and a ipallocation register, to associate at least one IP address to this port.
Reviewing the code of IPAllocation database object definition, “port_id” and “network_id” are foreign keys pointing to “ports.id” and “networks.id” respectively. A port register can have more than one IP address, stored in an ipallocation register. To follow the first normal form, the IP addresses are stored in a different table, “ipallocations“, considered as a child table of “ports“.
Having this information, how can we retrieve all ports, from a single network, that have IP address? Simple, querying for all ports with a ipallocation register associated and this ipallocation register should be in this network. This Python query will be translated into this SQL query:
SELECT
ports.project_id AS ports_project_id,
ports.id AS ports_id,
ports.name AS ports_name,
ports.network_id AS ports_network_id,
ports.mac_address AS ports_mac_address
FROM
ipallocations,
ports
WHERE
ipallocations.port_id = ports.id
AND ipallocations.network_id = '0e24a499-90c9-4b8e-86fe-634e425a0471'This is just a snippet of the full SQL query, but still functional.
What about the opposite query? What if we want the ports from this network but this time without an IP address associated? Now the query is a bit different. We first filter for those ports without an ipallocation register associated and then we filter again to collect only those ports in the chosen network. Again, this Python query will be translated into this SQL query:
SELECT
ports.project_id AS ports_project_id,
ports.id AS ports_id,
ports.name AS ports_name,
ports.network_id AS ports_network_id,
ports.mac_address AS ports_mac_address,
FROM
ports
WHERE
NOT (EXISTS(SELECT * FROM ipallocations
WHERE ipallocations.port_id = ports.id))
AND ports.network_id = '0e24a499-90c9-4b8e-86fe-634e425a0471'In a nutshell: although SQLAlchemy (or any other ORM) abstracts the database logic into Python objects, you need to have in mind that the query model needs to be converted into a SQL query; in complex queries, try first to model the SQL query you need.
Useful tools.
You will need, eventually, to execute some SQL queries to check the database content or to test your code. PostgreSQL, MariaDB or MySQL will give you a CLI interface to interact with the database. But let’s admit it, the interface is a bit stern. I use MySQL Workbench to query and inspect the database. Very intuitive.
Pycharm, as I commented in other posts, is my default Python editor. In debug mode, the oslo.db Query instances look like this:
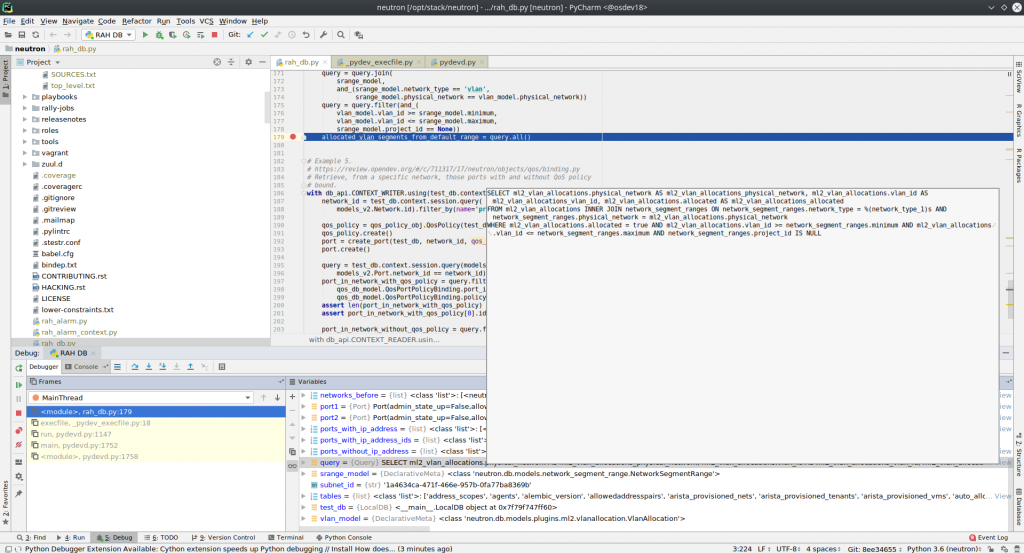
This is the SQL query that SQLAlchemy generates based on the Python API abstraction provided. You can copy this SQL code and execute it directly on the database.