
Welcome back! I just finished my lethargic aestival period, emerging from the swimming pool like a manatee. Back to the (awaited) office routine, I had a clash with Keepalived; actually with around four hundred instances. Yes, 400 instances spawned to control the same number of high availability routers in OpenStack.
The OpenStack L3 agent is in charge, among other operations, of deploying the routing infrastructure, depending on the selected configuration. In case of high availability, a router instance is spawned in each HA physical host. A router instance, in OpenStack, is a namespace connected to the networks routed via itself where the packets are routed using netfilter rules.
Those router instances use Virtual Router Redundancy Protocol (VRRP), via Keepalived. This protocol ensures only one instance is in active mode, while the other ones are in backup state. When a router becomes active, Keepalived sets the virtual routes on the namespace and IP addresses on the interfaces. Precisely on this transition is when the problems start. But first, let me explain just a bit what VRRP and Keepalived are.
VRRP protocol and Keepalived.
VRRP protocol “is a computer networking protocol that provides for automatic assignment of available Internet Protocol (IP) routers to participating hosts”. That means, VRRP is an election protocol that will dynamically assign an IP address to a single router in a pool of then in the same network. The protocol defines a virtual router, that is an abstract representation of multiple physical routers. Outside this abstraction, other systems only see one single gateway (one single IP address), belonging at that moment to a single physical router interface.
A VRRP virtual router uses the MAC address 00:00:5E:00:01:XX, being XX the Virtual Router Identifier (VRID), which is different for each virtual router in the network. Physical routers within the virtual router (that means, each instance spawned in a host which is part of a virtual router) must communicate within themselves using packets with multicast address 224.0.0.18 and IP protocol 112. In a nutshell, this is what you’ll see capturing in the HA interface:
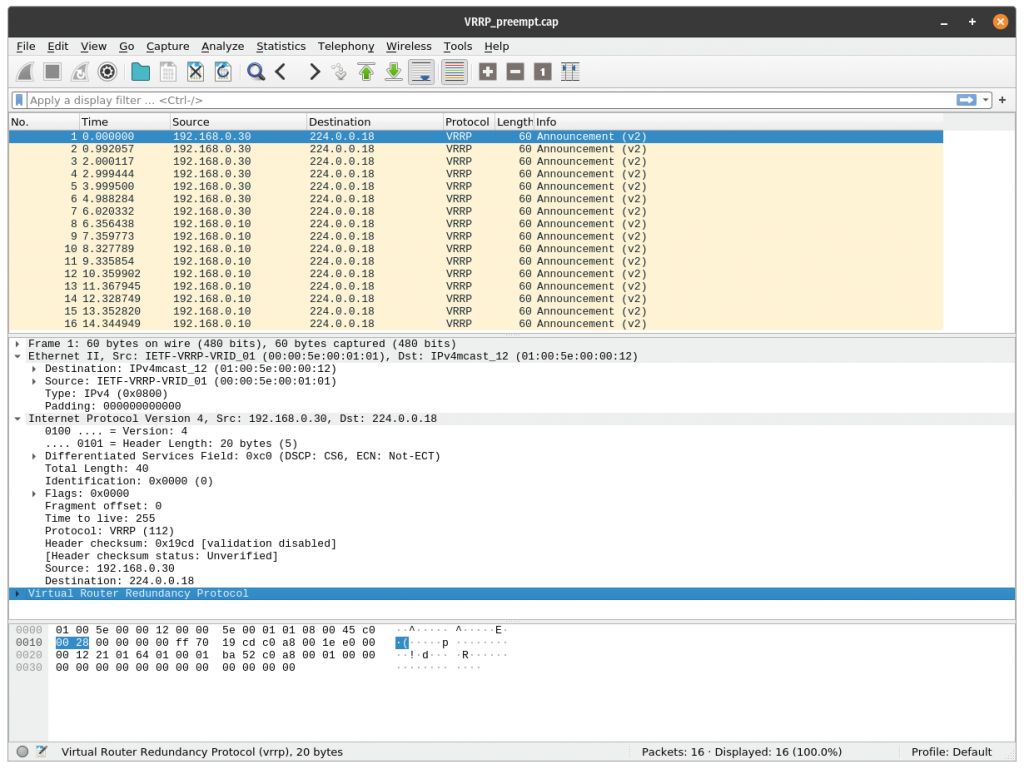
Active router is sending periodically a VRRP advertisement packet. When backup routers do not receive this packet in a period longer than three times the advertisement period, the active router is considered dead. The virtual router enters in a transition state to elect a new active router. The backup router with the highest priority becomes the new active router.
Keepalived is a service that provides load balancing and high-availability to Linux systems. It uses VRRP to provide the high-availability. I would recommend you to read the following articles to start digging into this topic:
- Using Keepalived for managing simple failover in clusters.
- Setting up a Linux cluster with Keepalived: Basic configuration.
- Keepalived and high availability: Advanced topics.
The problem and how we mitigated (not solved) it.
The environment is an Openstack deployment consisting of three beefy controller servers and several several compute nodes. Because the virtual routers are hosted in the controller nodes, the compute hosts are irrelevant here. When the OpenStack L3 agents are started, the routers, if not present in the hosts, are spawned sequentially. In this deployment, with 400 routers, this process takes some minutes. During this time, the physical router instances (and their Keepalived processes) belonging to a virtual router are started in each controller node. When a Keepalived instance is started, the voting process starts too. Each Keepalived starts sending the VRRP advertisements with the configured priority, that are received by the other Keepalived instances of the virtual router; that will decide the active instance. Once one instance is declared active, the VIPs are configured in the router interfaces. To populate in the network the new location (MAC address) of those IP addresses, several GARPs are sent per IP address in a fixed interval.
Everything runs smoothly until a fail-over occurs. Just when we need Keepalived the most, it becomes the problem. When one of the controllers is disconnected, the active router instances spawned on it are removed from the virtual routers. A third of those 400 virtual routers start a new voting process, sending multicast VRRP messages and GARPs once the VIPs are configured. The network backend, OVS, was unable to handle the torrent of multicast VRRP messages (to vote for a new active instance) and ARP packets. The Keepalived processes were continuously sending VRRP advertisement messages increasing the softirq queues CPU consumption until the system becomes unresponsive. After a quick exorcism (“$sudo reboot”), all the defunct and zombie processes rested in peace.
To mitigate (not to solve) this problem, we tweaked some Keepalived configuration parameters:
- The VRRP advertisement interval. This parameter defines the delay, in seconds, between two advertisement packets. Increasing this value we gave to the CPU more time to process all the incoming messages during a voting process. Of course, increasing this parameter implies that the transition time from backup to active is also increased. The virtual router response time to a failure is increased proportionally. The value of this parameter should be a compromise between response time, CPU power and the number of routers spawned in a single controller.
- The GARP delay and the GARP repeat. The GARP for each VIP assigned to a router that becomes active is sent several times. The first parameter controls the time waited between those sending; the second one controls how many times the GARP is sent. Increasing the delay and reducing the number of times the GARP for a single VIP is sent, reduces the burden of the network backend and the CPU.
Two easy tweaks to solve a difficult problem we had, but very effective. Please take a look at the Keepalived configuration section to realize the flexibility of this process and in how many ways it can be configured. For example, if, as we expected initially, the problem is on the multicast packets, you can configure Keepalived to run on unicast.
How to test Keepalived in your own computer.
And now the funny part, messing with the system. This section provides a quick way to test Keepalived and check experimentally how the VRRP protocol works in this implementation.
To test Keepalived you will need at least two instances; one will be the active one and the other one the backup (if there is communication between both). I’ve created a small environment with three namespaces, one to play the network switch role and the other two to host the Keepalived instances. Once you finish testing, you can clean up your environment just deleting the three namespaces.
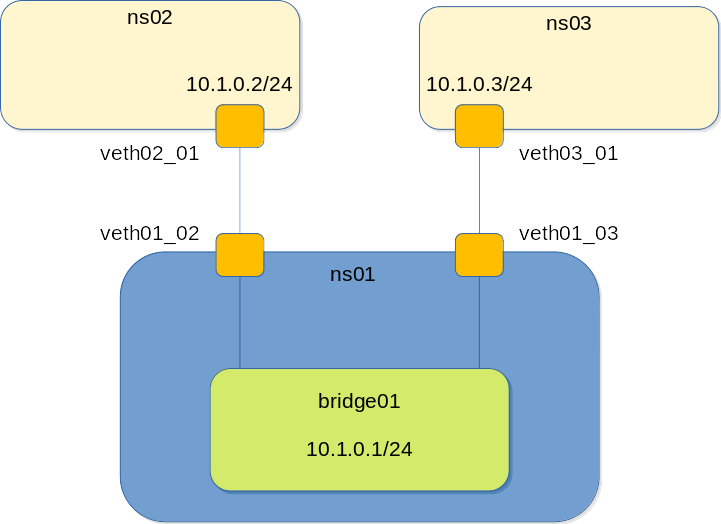
To build it you can execute the following commands:
ip netns add ns01 ip netns add ns02 ip netns add ns03 ip link add veth01_02 type veth peer name veth02_01 ip link set dev veth01_02 netns ns01 ip link set dev veth02_01 netns ns02 ip link add veth01_03 type veth peer name veth03_01 ip link set dev veth01_03 netns ns01 ip link set dev veth03_01 netns ns03 ip netns exec ns01 ip link set veth01_02 up ip netns exec ns01 ip link set veth01_03 up ip netns exec ns02 ip link set veth02_01 up ip netns exec ns03 ip link set veth03_01 up ip netns exec ns01 add bridge0 type bridge ip netns exec ns01 ip link add bridge0 type bridge ip netns exec ns01 ip link set dev bridge0 up ip netns exec ns01 ip a add 10.1.0.1/24 dev bridge0 ip netns exec ns01 ip link set veth01_02 master bridge0 ip netns exec ns01 ip link set veth01_03 master bridge0 ip netns exec ns02 ip a add 10.1.0.2/24 dev veth02_01 ip netns exec ns03 ip a add 10.1.0.3/24 dev veth03_01
Now you have you isolated namespaces to run the Keepalived instances that will act as compute nodes in this simulation. The next step is to create the configuration files. There are plenty of examples in the internet; the following ones contain the minimum set of parameters to run.
$ cat /tmp/keep02.conf
vrrp_instance VI_2 {
state BACKUP
interface veth02_01
virtual_router_id 51
priority 202
advert_int 1
authentication {
auth_type PASS
auth_pass pass
}
virtual_ipaddress {
10.1.0.10/24
}
}
$ cat /tmp/keep03.conf
vrrp_instance VI_3 {
state BACKUP
interface veth03_01
virtual_router_id 51
priority 203
advert_int 1
authentication {
auth_type PASS
auth_pass pass
}
virtual_ipaddress {
10.1.0.10/24
}
}
Notice the small differences between both configs: the instance name, the interface and the priority.
“Start your engines”.
To execute both Keepalived instances you’ll need to execute the following commands:
$ ip netns exec ns02 keepalived -f /tmp/keep02.conf -p /var/run/keep02.pid -r /var/run/keep02_vrrp.pid -c /var/run/keep02_checkers.pid $ ip netns exec ns03 keepalived -f /tmp/keep03.conf -p /var/run/keep03.pid -r /var/run/keep03_vrrp.pid -c /var/run/keep03_checkers.pid
Now you can capture the traffic in “bridge01” interface. You will see how, for example, both instances send the VRRP announcement packets to the same multicast IP address 224.0.0.18, as commented before. You’ll see too how VI_3, once it wins the voting process because of the higher priority, becomes master and sends the GARPs associated to the configured virtual IP address.
This is an example of traffic capture with the previous configuration:
289 288.147840219 10.1.0.2 → 224.0.0.18 VRRP 54 Announcement (v2) 290 289.149170757 10.1.0.2 → 224.0.0.18 VRRP 54 Announcement (v2) 291 290.150459728 10.1.0.2 → 224.0.0.18 VRRP 54 Announcement (v2) 292 290.781150191 10.1.0.3 → 224.0.0.22 IGMPv3 54 Membership Report / Leave group 224.0.0.18 293 290.833163104 10.1.0.3 → 224.0.0.22 IGMPv3 54 Membership Report / Join group 224.0.0.18 for any sources 294 291.151769259 10.1.0.2 → 224.0.0.18 VRRP 54 Announcement (v2) 295 291.269178990 10.1.0.3 → 224.0.0.22 IGMPv3 54 Membership Report / Join group 224.0.0.18 for any sources 296 292.152456908 10.1.0.2 → 224.0.0.18 VRRP 54 Announcement (v2) 298 293.153391474 10.1.0.3 → 224.0.0.18 VRRP 54 Announcement (v2) 299 294.154561143 ce:b8:43:a3:f4:6e → Broadcast ARP 42 Gratuitous ARP for 10.1.0.10 (Request) 304 294.154852499 10.1.0.3 → 224.0.0.18 VRRP 54 Announcement (v2) 305 295.155467814 10.1.0.3 → 224.0.0.18 VRRP 54 Announcement (v2) 306 296.156314649 10.1.0.3 → 224.0.0.18 VRRP 54 Announcement (v2) 307 297.156955655 10.1.0.3 → 224.0.0.18 VRRP 54 Announcement (v2) 308 298.157513686 10.1.0.3 → 224.0.0.18 VRRP 54 Announcement (v2) 309 299.155671882 ce:b8:43:a3:f4:6e → Broadcast ARP 42 Gratuitous ARP for 10.1.0.10 (Request) 314 299.157843563 10.1.0.3 → 224.0.0.18 VRRP 54 Announcement (v2) 315 300.158573557 10.1.0.3 → 224.0.0.18 VRRP 54 Announcement (v2) 316 301.159233499 10.1.0.3 → 224.0.0.18 VRRP 54 Announcement (v2) 317 302.159935692 10.1.0.3 → 224.0.0.18 VRRP 54 Announcement (v2) 318 303.160624007 10.1.0.3 → 224.0.0.18 VRRP 54 Announcement (v2)
With this small environment in place, you can play with the instance configuration files, changing the virtual router priority, the set of virtual IP addresses, the GARP parameters, etc. To reload an instance configuration, once you finished editing its config file, you need to send SIGHUP to the process.
I hope this small guide helps you to understand a bit better how the VRRP protocol and Keepalived work.